A lesser known, but particularly powerful feature of GStreamer is our ability to play media synchronised across devices with fairly good accuracy.
The way things stand right now, though, achieving this requires some amount of fiddling and a reasonably thorough knowledge of how GStreamer’s synchronisation mechanisms work. While we have had some excellent talks about these at previous GStreamer conferences, getting things to work is still a fair amount of effort for someone not well-versed with GStreamer.
As part of my work with the Samsung OSG, I’ve been working on addressing this problem, by wrapping all the complexity in a library. The intention is that anybody who wants to implement the ability for different devices on a network to play the same stream and have them all synchronised should be able to do so with a few lines of code, and the basic know-how for writing GStreamer-based applications.
I’ve started work on this already, and you can find the code in the creatively named gst-sync-server repo.
Design and API
Let’s make this easier by starting with a picture …
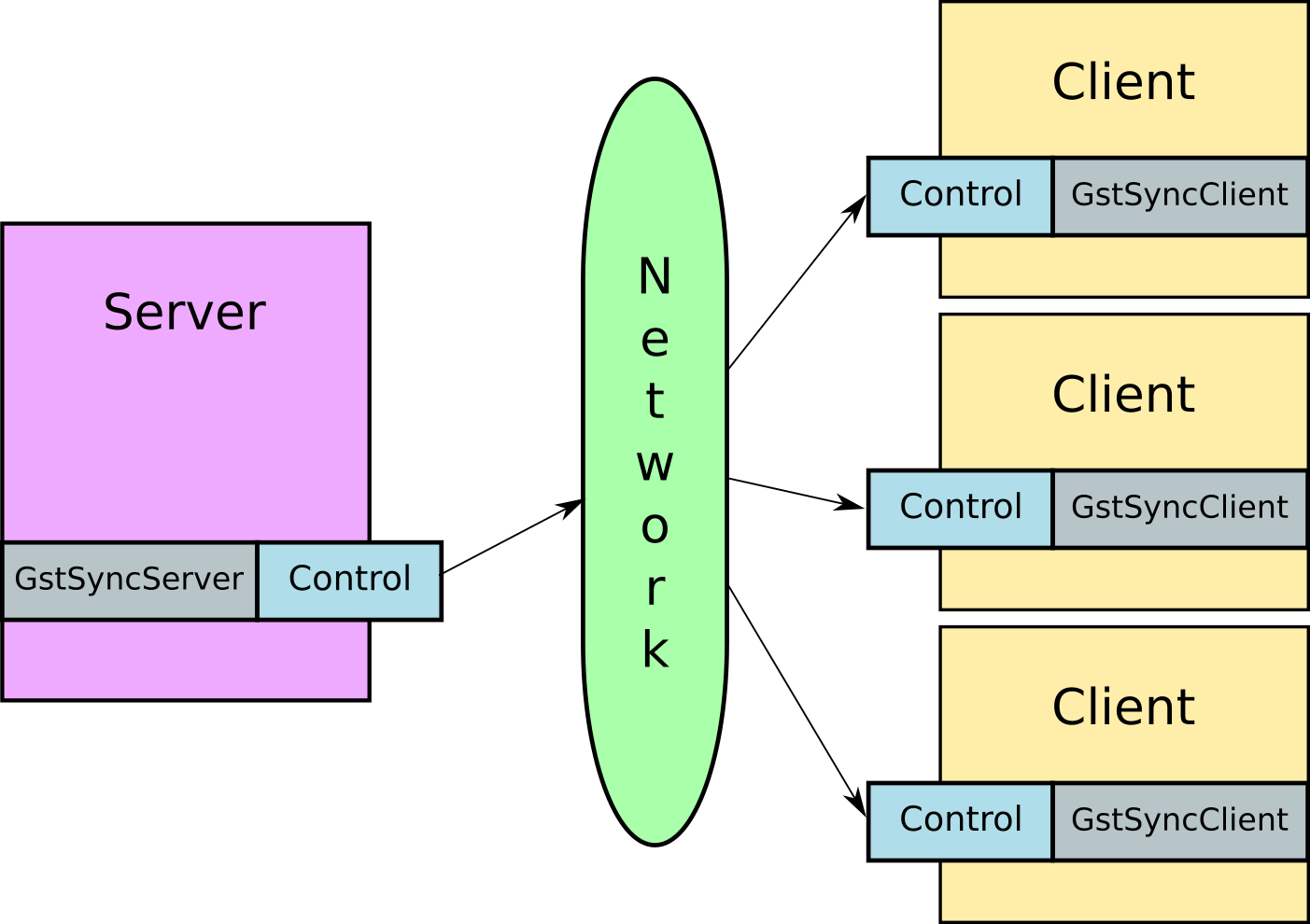
Let’s say you’re writing a simple application where you have two ore more devices that need to play the same video stream, in sync. Your system would consist of two entities:
A server: this is where you configure what needs to be played. It instantiates a
GstSyncServerobject on which it can set a URI that needs to be played. There are other controls available here that I’ll get to in a moment.A client: each device would be running a copy of the client, and would get information from the server telling it what to play, and what clock to use to make sure playback is synchronised. In practical terms, you do this by creating a
GstSyncClientobject, and giving it aplaybinelement which you’ve configured appropriately (this usually involves at least setting the appropriate video sink that integrates with your UI).
That’s pretty much it. Your application instantiates these two objects, starts them up, and as long as the clients can access the media URI, you magically have two synchronised streams on your devices.
Control
The keen observers among you would have noticed that there is a control entity in the above diagram that deals with communicating information from the server to clients over the network. While I have currently implemented a simple TCP protocol for this, my goal is to abstract out the control transport interface so that it is easy to drop in a custom transport (Websockets, a REST API, whatever).
The actual sync information is merely a structure marshalled into a JSON string and sent to clients every time something happens. Once your application has some media playing, the next thing you’ll want to do from your server is control playback. This can include
- Changing what media is playing (like after the current media ends)
- Pausing/resuming the media
- Seeking
- “Trick modes” such as fast forward or reverse playback
The first two of these work already, and seeking is on my short-term to-do list. Trick modes, as the name suggets, can be a bit more tricky, so I’ll likely get to them after other things are done.
Getting fancy
My hope is to see this library being used in a few other interesting use cases:
Video walls: having a number of displays stacked together so you have one giant display — these are all effectively playing different rectangles from the same video
Multiroom audio: you can play the same music across different speakers in a single room, or multiple rooms, or even group sets of speakers and play different media on different groups
Media sharing: being able to play music or videos on your phone and have your friends be able to listen/watch at the same time (a silent disco app?)
What next
At this point, the outline of what I think the API should look like is done. I still need to create the transport abstraction, but that’s pretty much a matter of extracting out the properties and signals that are part of the existing TCP transport.
What I would like is to hear from you, my dear readers who are interested in using this library — does the API look like it would work for you? Does the transport mechanism I describe above cover what you might need? There is example code that should make it easier to understand how this library is meant to be used.
Depending on the feedback I get, my next steps will be to implement the transport interface, refine the API a bit, fix a bunch of FIXMEs, and then see if this is something we can include in gst-plugins-bad.
Feel free to comment either on the Github repository, on this blog, or via email.
And don’t forget to watch this space for some videos and measurements of how GStreamer synchronised fares in real life!