In case you missed it — we got PulseAudio 9.0 out the door, with the echo cancellation improvements that I wrote about. Now is probably a good time for me to make good on my promise to expand upon the subject of beamforming.
As with the last post, I’d like to shout out to the wonderful folks at Aldebaran Robotics who made this work possible!
Beamforming
Beamforming as a concept is used in various aspects of signal processing including radio waves, but I’m going to be talking about it only as applied to audio. The basic idea is that if you have a number of microphones (a mic array) in some known arrangement, it is possible to “point” or steer the array in a particular direction, so sounds coming from that direction are made louder, while sounds from other directions are rendered softer (attenuated).
Practically speaking, it should be easy to see the value of this on a laptop, for example, where you might want to focus a mic array to point in front of the laptop, where the user probably is, and suppress sounds that might be coming from other locations. You can see an example of this in the webcam below. Notice the grilles on either side of the camera — there is a microphone behind each of these.

Webcam with 2 mics
This raises the question of how this effect is achieved. The simplest approach is called “delay-sum beamforming”. The key idea in this approach is that if we have an array of microphones that we want to steer the array at a particular angle, the sound we want to steer at will reach each microphone at a different time. This is illustrated below. The image is taken from this great article describing the principles and math in a lot more detail.
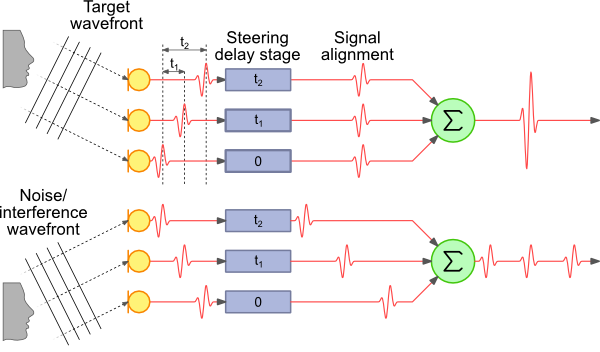
Delay-sum beamforming
In this figure, you can see that the sound from the source we want to listen to reaches the top-most microphone slightly before the next one, which in turn captures the audio slightly before the bottom-most microphone. If we know the distance between the microphones and the angle to which we want to steer the array, we can calculate the additional distance the sound has to travel to each microphone.
The speed of sound in air is roughly 340 m/s, and thus we can also calculate how much of a delay occurs between the same sound reaching each microphone. The signal at the first two microphones is delayed using this information, so that we can line up the signal from all three. Then we take the sum of the signal from all three (actually the average, but that’s not too important).
The signal from the direction we’re pointing in is going to be strongly correlated, so it will turn out loud and clear. Signals from other directions will end up being attenuated because they will only occur in one of the mics at a given point in time when we’re summing the signals — look at the noise wavefront in the illustration above as an example.
Implementation
(this section is a bit more technical than the rest of the article, feel free to skim through or skip ahead to the next section if it’s not your cup of tea!)
The devil is, of course, in the details. Given the microphone geometry and steering direction, calculating the expected delays is relatively easy. We capture audio at a fixed sample rate — let’s assume this is 32000 samples per second, or 32 kHz. That translates to one sample every 31.25 µs. So if we want to delay our signal by 125µs, we can just add a buffer of 4 samples (4 × 31.25 = 125). Sound travels about 4.25 cm in that time, so this is not an unrealistic example.
Now, instead, assume the signal needs to be delayed by 80 µs. This translates to 2.56 samples. We’re working in the digital domain — the mic has already converted the analog vibrations in the air into digital samples that have been provided to the CPU. This means that our buffer delay can either be 2 samples or 3, not 2.56. We need another way to add a fractional delay (else we’ll end up with errors in the sum).
There is a fair amount of academic work describing methods to perform filtering on a sample to provide a fractional delay. One common way is to apply an FIR filter. However, to keep things simple, the method I chose was the Thiran approximation — the literature suggests that it performs the task reasonably well, and has the advantage of not having to spend a whole lot of CPU cycles first transforming to the frequency domain (which an FIR filter requires)(edit: converting to the frequency domain isn’t necessary, thanks to the folks who pointed this out).
I’ve implemented all of this as a separate module in PulseAudio as a beamformer filter module.
Now it’s time for a confession. I’m a plumber, not a DSP ninja. My delay-sum beamformer doesn’t do a very good job. I suspect part of it is the limitation of the delay-sum approach, partly the use of an IIR filter (which the Thiran approximation is), and it’s also entirely possible there is a bug in my fractional delay implementation. Reviews and suggestions are welcome!
A Better Implementation
The astute reader has, by now, realised that we are already doing a bunch of processing on incoming audio during voice calls — I’ve written in the previous article about how the webrtc-audio-processing engine provides echo cancellation, acoustic gain control, voice activity detection, and a bunch of other features.
Another feature that the library provides is — you guessed it — beamforming. The engineers at Google (who clearly are DSP ninjas) have a pretty good beamformer implementation, and this is also available via module-echo-cancel. You do need to configure the microphone geometry yourself (which means you have to manually load the module at the moment). Details are on our wiki (thanks to Tanu for that!).
How well does this work? Let me show you. The image below is me talking to my laptop, which has two microphones about 4cm apart, on either side of the webcam, above the screen. First I move to the right of the laptop (about 60°, assuming straight ahead is 0°). Then I move to the left by about the same amount (the second speech spike). And finally I speak from the center (a couple of times, since I get distracted by my phone).
The upper section represents the microphone input — you’ll see two channels, one corresponding to each mic. The bottom part is the processed version, with echo cancellation, gain control, noise suppression, etc. and beamforming.
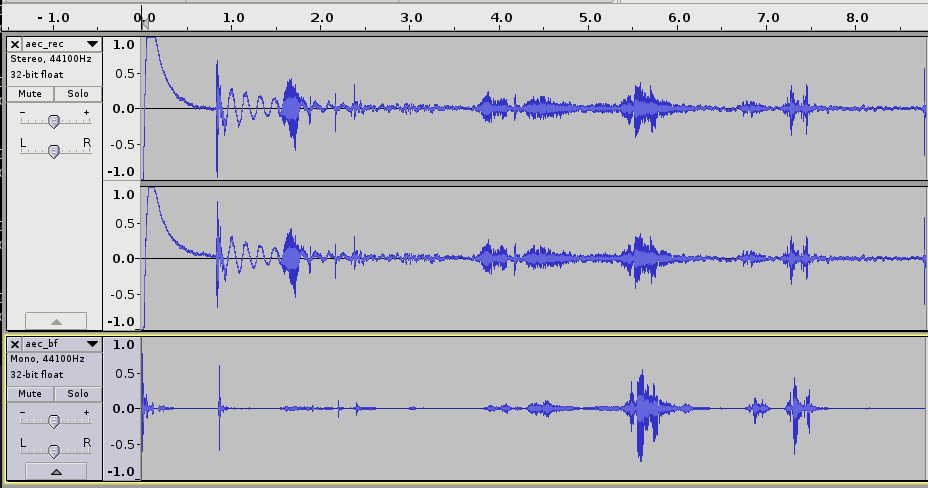
WebRTC beamforming
You can also listen to the actual recordings …
… and the processed output.
Feels like black magic, doesn’t it?
Finishing thoughts
The webrtc-audio-processing-based beamforming is already available for you to use. The downside is that you need to load the module manually, rather than have this automatically plugged in when needed (because we don’t have a way to store and retrieve the mic geometry). At some point, I would really like to implement a configuration framework within PulseAudio to allow users to set configuration from some external UI and have that be picked up as needed.
Nicolas Dufresne has done some work to wrap the webrtc-audio-processing library functionality in a GStreamer element (and this is in master now). Adding support for beamforming to the element would also be good to have.
The module-beamformer bits should be a good starting point for folks who want to wrap their own beamforming library and have it used in PulseAudio. Feel free to get in touch with me if you need help with that.
ao2
June 29, 2016 — 7:09 pm
Hi Arun, this is interesting, if you provide an example command line to load the needed modules with the mic_geometry parameter I could try providing mic geometries for the Kinect v1 and the PS3 Eye webcams.
Ciao, Antonio
Arun
June 29, 2016 — 8:29 pm
That’d be quite cool, indeed. I’ve updated the wiki with an example of how you could set up the mic geometry now — https://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/User/Modules/?updated#index45h3
Viraj
February 13, 2017 — 12:03 pm
hi, can you provide mic geometry for PS3 eye ?
Arun
February 20, 2017 — 12:32 pm
Hiya. I don’t have the hardware, so kind of difficult me to write this. It should just be a matter of locating the mics, and measuring the distances from the “center”.
DavidW
June 29, 2016 — 9:21 pm
That does sound like black magic. I’m excited to be able to try it.
What about the opposite use case? Multiple microphones for the purposes of capturing everything in a room. This could be useful for the web-conferences as a group.
Arun
June 29, 2016 — 11:54 pm
That should be quite possible — in the trivial case, it’s a question of mixing all the channels together. I can imagine it would be possible to be more intelligent and use features such as voice activity detection (which
webrtc-audio-processingprovides) to make decisions about which mic to provide emphasis on based on who’s speaking.Alexander E. Patrakov
June 30, 2016 — 1:33 am
Actually there is one problem with the demonstration or explanation here. Namely, your example configures the beamformer to listen to sounds from center. But, if we apply the knowledge about delay-sum beamforming to this configuration, we’ll immediately arrive to the conclusion that it’s sufficient to just sum the two channels, because the delay is the same – but this obviously doesn’t yield the impressing result that you have presented. So, webrtc-audio-processing does some extra magic (inter-channel delay estimation + gain control based on that?) in addition.
Arun
June 30, 2016 — 1:36 am
Right,
webrtc-audio-processingdoesn’t seem to be using the delay-sum method at all. Specifically, their code says (and I was not able to find this paper):// The implemented nonlinear postfilter algorithm taken from "A Robust Nonlinear // Beamforming Postprocessor" by Bastiaan Kleijn.Michael Gebetsroither
June 30, 2016 — 2:57 pm
A good source for such topics is “Springer Handbook of Speech Processing”: 45.3 – Multichannel accoustic echo cancellation 47 – Accoustic beamforming and postfiltering And the whole part 1 about Multichannel speech processing
and maybe some interesting indeas for “beamforming” which does not require the geometry to be known… “Acoustic Blind Source Separation in Reverberant and Noisy Environments” https://opus4.kobv.de/opus4-fau/oai/container/index/docId/516
But i’m also no signal processing export either…
zoro
February 21, 2023 — 1:23 pm
did you find the paper of beamforming used in webrtc, named A Robust Nonlinear Beamforming Postprocessor” by Bastiaan Kleijn.
Steinar Heimdal Gunderson
June 29, 2016 — 9:33 pm
Hi,
FIR filters don’t require transforming into the frequency domain; you can implement them directly in the time domain. If the filter is long, FFT-based approaches will indeed reduce computational complexity (as will Winograd), but for e.g. a filter length of 16 taps, I wouldn’t really bother.
Arun
June 29, 2016 — 11:58 pm
Thanks! That’s useful to know — it’s something for me to try out when I’m able to get back to this, so I can see if the IIR is to blame for the bad performance I see (phase delays, perhaps).
Rob
July 27, 2016 — 9:48 pm
Is it possible to aim the magic beam in real time, for example at a particular person (ie detected face rectangle) in a group standing in front of one of our robots?
Yihui
December 13, 2016 — 12:33 pm
Cool! How do you set the target_direction?
I tried
pacmd load-module module-echo-cancel use_master_format=1 aec_method=’webrtc’ aec_args='”beamforming=1 mic_geometry=-0.05,0,0,0.05,0,0 target_direction=0,0,0.5″‘
but it failed with error messsage “Module load fialed”
Without the target_direction argument, it can be loaded.
pacmd load-module module-echo-cancel use_master_format=1 aec_method=’webrtc’ aec_args='”beamforming=1 mic_geometry=-0.05,0,0,0.05,0,0″‘
Yihui
December 13, 2016 — 1:08 pm
I got it. Based on https://github.com/pulseaudio/pulseaudio/blob/master/src/modules/echo-cancel/webrtc.cc#L411 target_direction only supports targeting along the azimuth which means the last two parameters must be zero.
Arun
December 13, 2016 — 1:18 pm
Glad you figured it out! :)
vinod
April 27, 2017 — 4:05 pm
Hi all, i am working on delay and sum beamforming in time domain , i got sample difference between two mic.data which is 0.25m apart. but after that i don’t have any idea to steering the audio signal. can you guys help me to solve this problem?
Antoine
May 24, 2017 — 6:00 pm
Hi all, I’m currently trying to test beamforming (on PulseAudio 10.0 with Ubuntu 17.04) with a PS3 Eye. When I use the following command line
pacmd load-module module-echo-cancel use_master_format=1 aec_method=’webrtc’ aec_args='”noise_suppression=1 beamforming=1 mic_geometry=-0.03,0,0,-0.01,0,0,0.01,0,0,0.03,0,0″‘
I get the “Module load failed” error and when I set the beamforming argument to null, i don’t get error. Do you have any advice or solution to resolve my problem ?
Thank you in advance for your help
Fabiano
July 29, 2020 — 4:28 am
To avoid the locale parse bug in pulseaudio, try removing the decimal point and use exp float notation: mic_geometry=-3e-2,0e0,0e0,-1e-2,0e0,0e0,1e-2,0e0,0e0,3e-2,0e0,0e0
Arun
May 24, 2017 — 7:41 pm
Hiya, look at the PA server logs to figure out why that is. You can enable them at runtime with
pacmd set-log-level 4Antoine
May 25, 2017 — 2:16 am
Ok, I resolved my problem. I had the following error message “Failed to parse channel 0 in mic_geometry”. I had to change my decimal separator character. I changed it by using
LC_NUMERIC=C
and it works. Thank you again for your precious help.
Francois
December 21, 2017 — 8:28 am
Hi Arun, As I see in your code, for ‘target_direction’, it only supports targeting along the azimuth. If we can’t change other two parameters (e=0 and r=0), does it mean beamforming can only work in very short distance? And do you have plans to improve it in pulseaudio?
Carmelo
June 2, 2018 — 1:53 am
Pulseaudio module-echo-cancel does not load with the locale it_IT.utf8. If I run LC_NUMERIC = C pulseaudio works! My GNU/Linux distribution is Debian 9.4, the pulseaudio version is 10.0-1 + deb9u1. I hope this problem will be fixed in the next version. Furthermore if I set the parameters (e = 0 and r = 0) it works if I set them to other non-zero values, it returns me loading error.
If you have a microphone array and want to verify azimuth, I found this Java software that does not require installation and is open source ;-)
http://www.laurentcalmes.lu/soundloc_software.html
Żyźniewski
February 21, 2020 — 10:27 pm
How does it actually work with 2 omnidirectional mics? I think the algorithm is lost (can’t find the relative position?) and my voice sounds very distorted.
kenny
May 10, 2020 — 10:32 pm
can I use this on my headset to cancel noise I get while typing on my keyboard
Tran Quang Quan
September 24, 2020 — 11:27 pm
@Arun: can you send me(quancoltech@gmail.com) your file use for test beamforming (that mentioned in your article)?
Arun
September 25, 2020 — 12:16 am
Heya, I just recorded myself on the microphone. Both the recordings are available to download at:
https://arunraghavan.net/wp-content/uploads/aec_rec.mp3
https://arunraghavan.net/wp-content/uploads/aec_bf.mp3
Denis Shulyaka
December 28, 2020 — 9:34 pm
Was beamforming just deleted? Why?
Arun
January 13, 2021 — 3:09 am
Unfortunately, it was dropped upstream
Stuart Naylor
June 28, 2021 — 6:24 pm
Arun with opensource voiceai being more prevalent is there any chance other options for beamforming may be included as to have C compiled filters in a audio framework is just brilliant.
I am not all that bothered about the remove upstream as that beamformer only worked on near field, but some form of beamforming would be a great addition.
Arun
July 20, 2021 — 5:31 pm
Hey Stuart, I do think such an addition would be valuable indeed. Do you know of any existing implementations that might be interesting to integrate?
Anton
November 27, 2023 — 10:13 pm
is this deprecated? i heard that webrtc removed the code
Arun
November 28, 2023 — 1:39 am
Hi Anton, yes that’s right — the beamformer was dropped from the
libwebrtccodebase, so is not supported in current versions ofwebrtc-audio-processing.