This is a quick PSA for those of you using the GStreamer binary builds for Android.
With the Android NDK r12, the default behaviour while building native code changed from building for armeabi to building for all ABIs. So if your app doesn’t specify APP_ABI in its Application.mk, you will now get an error about unsupported architectures. This was tracked as bug 770631.
The idea behind this change is that your Android app should ship versions of your native code for all supported architectures as a “universal” build, so it is accessible to as many devices as possible.
To deal with this, we now provide a universal tarball which contains binaries for all archiectures that we support. This is currently ARM, ARMv7-A, ARMv8-A (64-bit), x86, and x86-64. That leaves MIPS and MIPS64 that are not currently supported.
If you’ve been using the GStreamer Android binaries before GStreamer 1.9.2, then you should start using the universal tarball rather than the architecture-specific tarball. You will need minor updates to your native build, like we made to the player example. You probably want to put the gstAndroidRoot variable in ~/.gradle/gradle.properties instead, though.
As Sebastian announced, assuming all goes well with the universal tarballs, we will stop shipping the per-arch tarballs — they are redundant, and just take up CI and disk resources.
There are some things that I’d like for us to be able to do better. The first is that Android Studio doesn’t pick up native code with our current build approach. This is a limitation of the Android Gradle NDK plugin, which doesn’t support a custom build. This should change with Android Studio 2.2.
I would also like to integrate better with Android Studio — either be able to specify the GStreamer Android binary path in the UI (like you do for the SDK/NDK), or better yet, have it be possible to specify the dependency in Gradle, and have it be automatically pulled from the Internet. If any of you are familiar with how we can do this, please shout out!
In case you missed it — we got PulseAudio 9.0 out the door, with the echo cancellation improvements that I wrote about. Now is probably a good time for me to make good on my promise to expand upon the subject of beamforming.
As with the last post, I’d like to shout out to the wonderful folks at Aldebaran Robotics who made this work possible!
Beamforming
Beamforming as a concept is used in various aspects of signal processing including radio waves, but I’m going to be talking about it only as applied to audio. The basic idea is that if you have a number of microphones (a mic array) in some known arrangement, it is possible to “point” or steer the array in a particular direction, so sounds coming from that direction are made louder, while sounds from other directions are rendered softer (attenuated).
Practically speaking, it should be easy to see the value of this on a laptop, for example, where you might want to focus a mic array to point in front of the laptop, where the user probably is, and suppress sounds that might be coming from other locations. You can see an example of this in the webcam below. Notice the grilles on either side of the camera — there is a microphone behind each of these.
Webcam with 2 mics
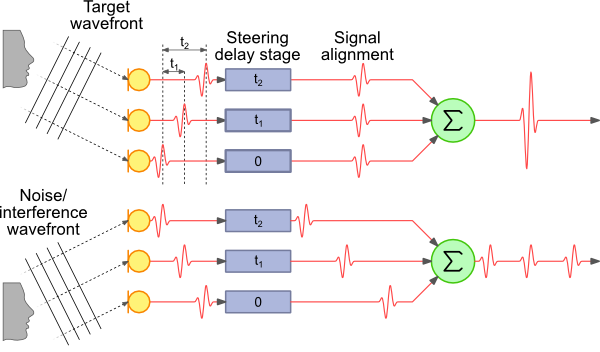
This raises the question of how this effect is achieved. The simplest approach is called “delay-sum beamforming”. The key idea in this approach is that if we have an array of microphones that we want to steer the array at a particular angle, the sound we want to steer at will reach each microphone at a different time. This is illustrated below. The image is taken from this great article describing the principles and math in a lot more detail.
Delay-sum beamforming
In this figure, you can see that the sound from the source we want to listen to reaches the top-most microphone slightly before the next one, which in turn captures the audio slightly before the bottom-most microphone. If we know the distance between the microphones and the angle to which we want to steer the array, we can calculate the additional distance the sound has to travel to each microphone.
The speed of sound in air is roughly 340 m/s, and thus we can also calculate how much of a delay occurs between the same sound reaching each microphone. The signal at the first two microphones is delayed using this information, so that we can line up the signal from all three. Then we take the sum of the signal from all three (actually the average, but that’s not too important).
The signal from the direction we’re pointing in is going to be strongly correlated, so it will turn out loud and clear. Signals from other directions will end up being attenuated because they will only occur in one of the mics at a given point in time when we’re summing the signals — look at the noise wavefront in the illustration above as an example.
Implementation
(this section is a bit more technical than the rest of the article, feel free to skim through or skip ahead to the next section if it’s not your cup of tea!)
The devil is, of course, in the details. Given the microphone geometry and steering direction, calculating the expected delays is relatively easy. We capture audio at a fixed sample rate — let’s assume this is 32000 samples per second, or 32 kHz. That translates to one sample every 31.25 µs. So if we want to delay our signal by 125µs, we can just add a buffer of 4 samples (4 × 31.25 = 125). Sound travels about 4.25 cm in that time, so this is not an unrealistic example.
Now, instead, assume the signal needs to be delayed by 80 µs. This translates to 2.56 samples. We’re working in the digital domain — the mic has already converted the analog vibrations in the air into digital samples that have been provided to the CPU. This means that our buffer delay can either be 2 samples or 3, not 2.56. We need another way to add a fractional delay (else we’ll end up with errors in the sum).
There is a fair amount of academic work describing methods to perform filtering on a sample to provide a fractional delay. One common way is to apply an FIR filter. However, to keep things simple, the method I chose was the Thiran approximation — the literature suggests that it performs the task reasonably well, and has the advantage of not having to spend a whole lot of CPU cycles first transforming to the frequency domain (which an FIR filter requires)(edit: converting to the frequency domain isn’t necessary, thanks to the folks who pointed this out).
Now it’s time for a confession. I’m a plumber, not a DSP ninja. My delay-sum beamformer doesn’t do a very good job. I suspect part of it is the limitation of the delay-sum approach, partly the use of an IIR filter (which the Thiran approximation is), and it’s also entirely possible there is a bug in my fractional delay implementation. Reviews and suggestions are welcome!
A Better Implementation
The astute reader has, by now, realised that we are already doing a bunch of processing on incoming audio during voice calls — I’ve written in the previous article about how the webrtc-audio-processing engine provides echo cancellation, acoustic gain control, voice activity detection, and a bunch of other features.
Another feature that the library provides is — you guessed it — beamforming. The engineers at Google (who clearly are DSP ninjas) have a pretty good beamformer implementation, and this is also available via module-echo-cancel. You do need to configure the microphone geometry yourself (which means you have to manually load the module at the moment). Details are on our wiki (thanks to Tanu for that!).
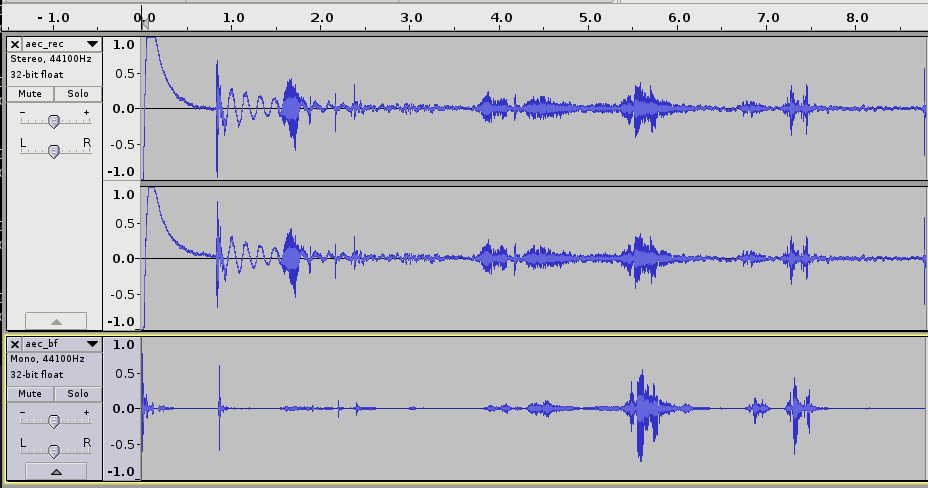
How well does this work? Let me show you. The image below is me talking to my laptop, which has two microphones about 4cm apart, on either side of the webcam, above the screen. First I move to the right of the laptop (about 60°, assuming straight ahead is 0°). Then I move to the left by about the same amount (the second speech spike). And finally I speak from the center (a couple of times, since I get distracted by my phone).
The upper section represents the microphone input — you’ll see two channels, one corresponding to each mic. The bottom part is the processed version, with echo cancellation, gain control, noise suppression, etc. and beamforming.
WebRTC beamforming
You can also listen to the actual recordings …
… and the processed output.
Feels like black magic, doesn’t it?
Finishing thoughts
The webrtc-audio-processing-based beamforming is already available for you to use. The downside is that you need to load the module manually, rather than have this automatically plugged in when needed (because we don’t have a way to store and retrieve the mic geometry). At some point, I would really like to implement a configuration framework within PulseAudio to allow users to set configuration from some external UI and have that be picked up as needed.
Nicolas Dufresne has done some work to wrap the webrtc-audio-processing library functionality in a GStreamer element (and this is in master now). Adding support for beamforming to the element would also be good to have.
The module-beamformer bits should be a good starting point for folks who want to wrap their own beamforming library and have it used in PulseAudio. Feel free to get in touch with me if you need help with that.
As we approach the PulseAudio 9.0 release, I thought it would be a good time to talk about one of the things I had a chance to work on, that landed in this cycle.
Old-time readers will remember the work I had done in the past on echo cancellation. If you’re unfamiliar with the concept, imagine a situation where you’re making a call from your phone or laptop. You don’t have a headset, so you use your device’s speaker and microphone. Now when the person on the other end speaks, their voice is played out of your speaker and captured by your mic. This means that they can now also hear what they’re saying, with some lag — this is called echo. If this has happened to you, you know how annoying and disruptive it can be.
Using Acoustic Echo Cancellation (AEC), PulseAudio is able to detect this in the captured input, and remove the audio we recently played back. While doing this, we also run some other algorithms to enhance the captured input, such as noise suppression (great at damping out background and fan noise) and acoustic gain control, or AGC, which adjusts the mic volume so you are clearly audible). In addition to voice call use cases, this is also handy to have in other applications such as speech recognition (where you want the device to detect what a user is saying, while possibly playing out other sounds).
We don’t implement these algorithms ourselves in PulseAudio. The echo cancellation module — cunningly named module-echo-cancel — provides the infrastructure to plug in different echo canceller implementations. One of these that we support (and recommend), is based on Google’s [WebRTC.org] implementation which includes an extremely capable set of voice processing algorithms.
This is a large code-base, intended to support a full real-time communication stack, and we didn’t want to pick up all that code to include in PulseAudio. So what I did was to make a copy of the AudioProcessing module, wrap it in an easy-to-package library, and then used that from PulseAudio. Quite some time passed by, and I didn’t get a chance to update that code, until last October.
What’s New
The update brought us a number of things since the last one (5 years ago!):
The AGC module has essentially been rewritten. In practice, we see that it is slower to change the volume.
Voice Activity Detection (VAD) has also been split off into its own module and undergone significant changes.
Beamforming has been added, to allow you to use a set of microphones to be able to “point” your microphone array in a specific direction (more on this in a later post).
There is now an intelligibility enhancer for applying processing on the stream coming in from the far end (so you can hear the other side better). This feature has not been hooked up in PulseAudio yet.
There is a transient suppressor for when you’re on a laptop, and your microphone is picking up keystrokes. This can be important since the sound of the keystroke introduces sharp spikes or “transients” in the audio stream, which can throw off the echo canceller that works best with the frequency range of the human voice. This one seems to be work-in-progress, and not actually used yet.
In addition to this, I’ve also extended support in module-echo-cancel for performing cancellation on multiple channels. So we are now able to deal with hardware that has any number of playback and capture channels (and they don’t even need to be equal), and we no longer have the artificial restriction of having to downmix things to mono.
These changes are in the newly released webrtc-audio-processing v0.2. Unfortunately, we do break API with regards to the previous version. I wrote about this a while back, and hopefully the impact on other users of this library will be minimal.
All this work was made possible thanks to Aldebaran Robotics. A special shout-out to Julien Massot and his excellent team!
These features are already in our master branch, and will be part of the 9.0 release. If you’re using these features, let me know how things work for you, and watch out for a follow up post about beamforming.
If you or your company are looking for help with either PulseAudio or GStreamer, do take a look at the consulting services I currently provide.
This one’s going to be a bit of a long post. You might want to grab a cup of coffee before you jump in!
Over the last few years, I’ve spent some time getting PulseAudio up and running on a few Android-based phones. There was the initial Galaxy Nexus port, a proof-of-concept port of Firefox OS (git) to use PulseAudio instead of AudioFlinger on a Nexus 4, and most recently, a port of Firefox OS to use PulseAudio on the first gen Moto G and last year’s Sony Xperia Z3 Compact (git).
The process so far has been largely manual and painstaking, and I’ve been trying to make that easier. But before I talk about the how of that, let’s see how all this works in the first place.
While I did mention a while back (almost two years ago, wow) that I was taking a break, I realised recently that I hadn’t posted an update from when I started again.
For the last year and a half, I’ve been providing freelance consulting around PulseAudio, GStreamer, and various other directly and tangentially related projects. There’s a brief list of the kind of work I’ve been involved in.
If you’re looking for help with PulseAudio, GStreamer, multimedia middleware or anything else you might’ve come across on this blog, do get in touch!
Thanks to everyone who contributed with bug reports and testing. What isn’t generally visible is that a lot of this happens behind the scenes downstream on distribution bug trackers, IRC, and so forth.
I know it’s been ages, but I am now working on updating the webrtc-audio-processing library. You might remember this as the code that we split off from the webrtc.org code to use in the PulseAudio echo cancellation module.
This is basically just the AudioProcessing module, bundled as a standalone library so that we can use the fantastic AEC, AGC, and noise suppression implementation from that code base. For packaging simplicity, I made a copy of the necessary code, and wrote an autotools-based build system around that.
Now since I last copied the code, the library API has changed a bit — nothing drastic, just a few minor cleanups and removed API. This wouldn’t normally be a big deal since this code isn’t actually published as external API — it’s mostly embedded in the Chromium and Firefox trees, probably other projects too.
Since we are exposing a copy of this code as a standalone library, this means that there are two options — we could (a) just break the API, and all dependent code needs to be updated to be able to use the new version, or (b) write a small wrapper to try to maintain backwards compatibility.
I’m inclined to just break API and release a new version of the library which is not backwards compatible. My rationale for this is that I’d like to keep the code as close to what is upstream as possible, and over time it could become painful to maintain a bunch of backwards-compatibility code.
A nicer solution would be to work with upstream to make it possible to build the AudioProcessing module as a standalone library. While the folks upstream seemed amenable to the idea when this came up a few years ago, nobody has stepped up to actually do the work for this. In the mean time, a number of interesting features have been added to the module, and it would be good to pull this in to use in PulseAudio and any other projects using this code (more about this in a follow-up post).
So if you’re using webrtc-audio-processing, be warned that the next release will probably break API, and you’ll need to update your code. I’ll try to publish a quick update guide when releasing the code, but if you want to look at the current API, take a look at the current audio_processing.h.
p.s.: If you do use webrtc-audio-processing as a dependency, I’d love to hear about it. As far as I know, PulseAudio is the only user of this library at the moment.
This one’s a bit late, for reasons that’ll be clear enough later in this post. I had the happy opportunity to go to GUADEC in Gothenburg this year (after missing the last two, unfortunately). It was a great, well-organised event, and I felt super-charged again, meeting all the people making GNOME better every day.
GUADEC picnic @ Gothenberg
I presented a status update of what we’ve been up to in the PulseAudio world in the past few years. Amazingly, all the videos are up already, so you can catch up with anything that you might have missed here.
We also had a meeting of PulseAudio developers which and a number of interesting topics of discussion came up (I’ll try to summarise my notes in a separate post).
A bunch of other interesting discussions happened in the hallways, and I’ll write about that if my investigations take me some place interesting.
Now the downside — I ended up missing the BoF part of GUADEC, and all of the GStreamer hackfest in Montpellier after. As it happens, I contracted dengue and I’m still recovering from this. Fortunately it was the lesser (non-haemorrhagic) version without any complications, so now it’s just a matter of resting till I’ve recuperated completely.
Nevertheless, the first part of the trip was great, and I’d like to thank the GNOME Foundation for sponsoring my travel and stay, without which I would have missed out on all the GUADEC fun this year.
I was in Depok, Indonesia last week to speak at GNOME Asia 2015. It was a great experience — the organisers did a fantastic job and as a bonus, the venue was incredibly pretty!
View from our room
My talk was about the GNOME audio stack, and my original intention was to talk a bit about the APIs, how to use them, and how to choose which to use. After the first day, though, I felt like a more high-level view of the pieces would be more useful to the audience, so I adjusted the focus a bit. My slides are up here.
Nirbheek and I then spent a couple of days going down to Yogyakarta to cycle around, visit some temples, and sip some fine hipster coffee.
All in all, it was a week well spent. I’d like to thank the GNOME Foundation for helping me get to the conference!
This might be a well-known trick already, but just in case it’s not…
Reviewing a patch can be a bit painful when a file that has been changed and moved or renamed at one go (and there can be perfectly valid reasons for doing this). A nice thing about git is that you can reference files in an arbitrary tree while using git diff, so reviewing such changes can become easier if you do something like this:
$ git am 0001-the-thing-I-need-to-review.patch
$ git diff HEAD^:old/path/to/file.c new/path/to/file.c
This just references file.c in its old path, which is available in the commit before HEAD, and compares it to the file at the new path in the patch you just merged.
Of course, you can also use this to diff a file at some arbitrary point in the past, or in some arbitrary branch, with the same file at the current HEAD or any other point.
Hopefully this is helpful to someone out there!
Update: As Alex Elsayed points out in the comments, git diff -M/-C can be used to similar effect. The above example, for example, could be written as:
$ git am 0001-the-thing-I-need-to-review.patch
$ git show -C